Relational Database Management System¶
Architecture of RDBMS¶

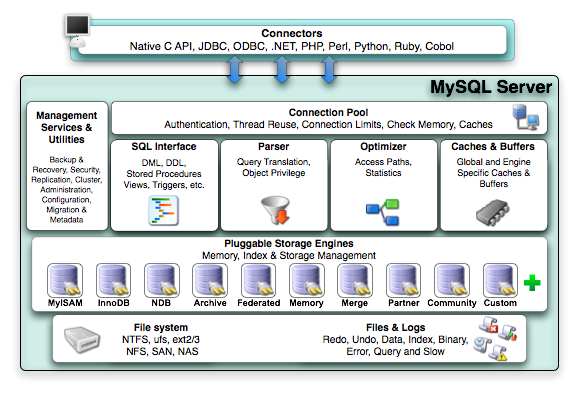
Example: Mysql
Characteristics of Transactions - ACID¶
- Atomicity
- Consistency
- Isolation
- Durability
Transaction Isolation Levels in RDBMS¶
- Read Uncommitted – The lowest isolation level. One transaction may read not yet committed changes made by other transaction, thereby allowing dirty reads. In this level, transactions are not isolated from each other.
- Read Committed – One transaction can read the data committed by other transactions.(Oracle, PostgreSQL)

- Repeatable Read – The most restrictive isolation level. Data read in a transaction is always consistent regardless of whether another transaction commits or not. (MySQL)

- Serializable – The Highest isolation level. Transactions will be executed one by one. Only one transaction can be running at meantime.
MVCC(Mutli-Version Concurrency Control)¶
The core idea is that there is no locking during reading,reading and writing of data have no conflict.
MVCC is implemented mainly by Undo Log and Read View.
-
Undo Log: stores historical versions of a record generated by each transaction. A historical version is a snapshot.
-
Read View: decides which version of the record can be seen in this transaction. When to generate the Read View decides the Isolation level. For example: In RR, Read View is generated only once at the first Select through the whole transaction. In RC, every select generates a new Read View, so the transaction can see the value committed by other transactions.
Example: MySQL

Snapshot Read:
Current Read:
-- add read lock:
select * from table where ? lock in share mode;
-- add write lock:
select * from table where ? for update;
insert into table values (...);
update table set ? where ?;
delete from table where ?;
DB Optimization Strategy¶
-
Identify Slow Sql, check execution plan by
explain sqland get insights into the number of rows could be scanned, the hit indexes, joins and operations, etc. -
Archive historical records, to reduce the number of rows of the big table.
-
Sharding (table oder database).
If the total amount of data for the query is too big, we can do table sharding, to reduce the data one query should scan.
if concurrency is too high, we can do database sharding, distributing concurrent requests across multiple instances.